Mixture-of-Experts: The artificial intelligence landscape is currently dominated by the remarkable capabilities of Large Language Models (LLMs). Systems like ChatGPT, Gemini, and Claude excel at understanding language, solving problems, writing code, and performing creative tasks. Their power seems almost magical.
However, behind this magic lies a significant engineering challenge: scaling. Historically, the path to more capable LLMs involved dramatically increasing their size – specifically, the number of parameters they contain. Consequently, there was a significant rise in the computational requirements for both training and inference.
Training these giants demands vast datasets and immense computing power, often taking weeks or months on thousands of GPUs or TPUs. Running them for inference (generating responses) also demands significant computational resources, leading to latency issues and high operational costs. This scaling challenge created a bottleneck: how can we enhance LLM intelligence without overwhelming computational costs and complexity?
Enter Mixture-of-Experts (MoE), an architectural paradigm that offers an elegant solution. MoE enables models to expand in parameters, boosting their knowledge capacity, without a corresponding rise in computation per inference step. It’s about scaling smarter, not just harder. Models such as Mistral AI’s Mixtral 8x7B and DeepSeek-AI’s DeepSeek-V2 showcase the power of MoE in the open-source arena, while major players like Google and OpenAI are believed to leverage comparable strategies behind the scenes in their proprietary systems.
This article provides a deep dive into the Mixture-of-Experts architecture. We will explore what it is, how it works, why it’s crucial, the challenges it presents, and its real-world applications, especially in programming and legal analysis. This is intended for technical professionals familiar with basic LLM concepts who want a thorough understanding of this transformative architecture.
The Wall: Understanding the Limits of Traditional Dense Models
Before appreciating MoE, let’s briefly revisit the standard “dense” Transformer architecture that powered many earlier LLMs. Transformers rely on mechanisms like self-attention (allowing models to weigh the importance of different words in the input sequence) and Feed-Forward Networks (FFNs) within each layer to process information.
In a traditional dense model, every parameter participates in the computation for every single token that flows through it. When a token representation enters a Transformer block’s FFN sub-layer, it passes through all the neurons and weights of that FFN.
As models expand, this “all hands on deck” strategy becomes increasingly costly in terms of computation. While self-attention complexity scales quadratically with sequence length \(O(N^2)\), the FFN layers also contribute significantly to the computational load, scaling with the number of parameters.Enhancing performance by expanding hidden dimensions or adding more layers significantly raises the number of floating point operations (FLOPs) needed for each token.
The consequences are stark. Training a dense model with trillions of parameters becomes astronomically expensive, requiring hardware resources available only to a few major players. Inference latency increases, making real-time applications challenging. Perhaps most critically, the model’s entire weight set needs to fit into the available accelerator memory (GPU VRAM or TPU memory), which becomes a major hardware limitation for extremely large dense models. Pushing the boundaries of dense models meant pushing the boundaries of hardware and budget, an unsustainable path for continued rapid progress.
Enter the Specialists: What is Mixture-of-Experts (MoE)?
Mixture-of-Experts tackles the scaling problem by introducing the concept of conditional computation. The core idea is simple yet profound: instead of activating the entire network for every input, activate only the relevant parts. It’s about selectively engaging computational resources based on the specific nature of the input token being processed.
Think of a large general hospital versus a specialized clinic network. A dense model is like the single, large hospital where every patient might pass through various general departments. An MoE model is more like the specialized network. There’s a central coordinator (the router) who assesses the incoming patient’s (token’s) needs and directs them to one or two highly specialized clinics (the experts) best suited for their specific issue. Only those selected clinics activate their resources.
Let’s break down the core components of an MoE layer, which typically replaces the standard FFN sub-layer within a Transformer block:
- Experts: These are the specialized sub-networks. In most LLM implementations, each expert is itself a neural network, often having the same architecture as the FFN it replaces (e.g., a two-layer MLP). Each expert is equipped with its own uniquely trainable parameters, allowing them to specialize independently. An MoE layer might contain anywhere from a few (like 8 in Mixtral) to many (64 or more, as in some configurations of DeepSeek-V2) experts.
- Router (or Gating Network): This is the coordinator. It’s typically a small, lightweight neural network (often just a single linear layer) whose job is to decide which expert(s) should process the current input token. It takes the token’s representation (embedding) as input and outputs a set of scores or probabilities, one for each expert, indicating that expert’s predicted suitability for the token. The router’s parameters are also learned during training.
It’s essential to differentiate MoE from conventional ensemble methods. Ensembling typically involves training multiple separate models and then averaging their predictions. In ensembles, all models run for every input. In MoE, the experts are part of a single, larger model, and crucially, only a small subset of experts is computationally activated for any given input token. This sparsity is the key to MoE’s efficiency.
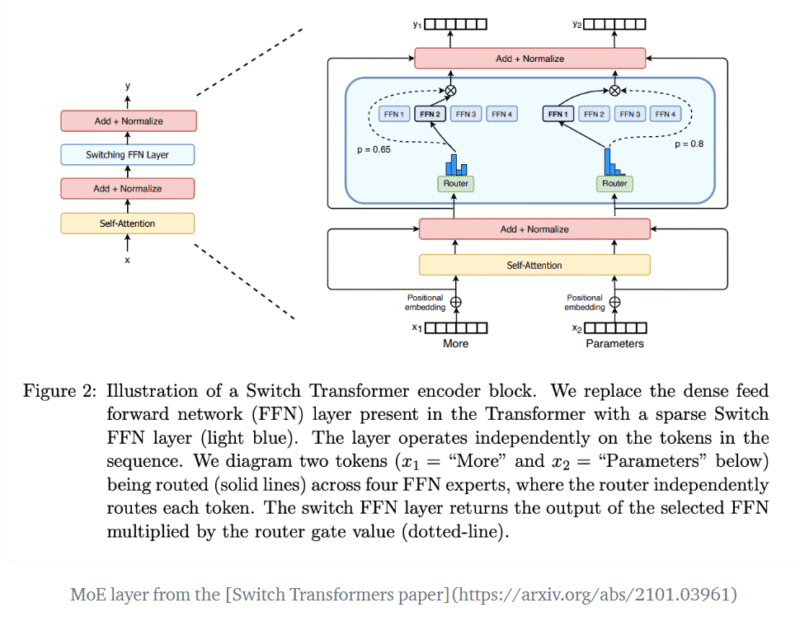
The Routing Dance: How MoE Works Mechanically
The magic of MoE lies in the dynamic routing process that occurs for each token within an input sequence. Let’s trace the journey of a single token representation as it passes through an MoE layer:
- Arrival: The token’s vector representation (embedding) arrives at the MoE layer from the preceding layer (e.g., the self-attention sub-layer). Let’s denote this vector as x.
- Router Calculation: The token vector x is fed into the router network. This process usually entails a straightforward linear operation: \(s=W_r⋅x\), where \(W_r\) represents the router’s learnable weight matrix, shaped according to the model’s dimensionality (with dimensions \(d_{model}\) . The resulting vector s holds unprocessed scores corresponding to each expert.
- Expert Selection (Top-K Routing): The most common strategy is Top-K routing. The router identifies the K experts corresponding to the highest scores in the vector s. The value of K is a hyperparameter, typically small (e.g., K=1, 2, 4, or 6).
- For instance, Mixtral 8x7B uses 8 experts per MoE layer and selects the Top-K=2 experts for each token.
- DeepSeek-V2 uses a more complex setup with 64 “routed” experts and 2 “shared” experts (which are always active), selecting K=6 from the routed experts for each token.
- Using K>1 is often found to improve model performance and training stability compared to selecting only the single best expert (K=1), as it allows tokens to benefit from a combination of specialized perspectives.
- Sparse Activation: This is where the computational savings occur. Only the selected Top-K experts perform their computations on the input token x. The parameters (weights) of the other num_experts)-K experts remain dormant for this specific token. They are not involved in the forward pass calculation.
- Expert Processing: Each of the K selected experts processes the token x using its own distinct weights: \(y_i=Expert_i(x)\) for each selected expert i.
- Output Combination: The outputs \(yi\) from the K active experts need to be combined to produce the final output of the MoE layer for that token. This is typically done using a weighted sum, where the weights are derived from the router’s scores. Often, the router’s raw scores (s) for the selected Top-K experts are normalized (e.g., using a Softmax function applied only to the scores of the selected experts) to get gating weights gi. The final output y is then calculated as: \[y=\sum_{i∈TopK}^{}g_i⋅y_i\].
Example Scenario: Consider a Mixture-of-Experts (MoE) layer comprising four experts (E1, E2, E3, E4) with Top-K routing set to 2.
- A token representation x arrives.
- The router computes scores: s=[3.1,−0.5,4.5,1.2].
- Top-K=2 selection identifies E3 (score 4.5) and E1 (score 3.1) as the active experts.
- E1 computes y1=E1(x) and E3 computes y3=E3(x). E2 and E4 do nothing for this token.
- The router scores for E1 and E3 (3.1, 4.5) are normalized (e.g., via Softmax over these two values) to get gating weights, say g1=0.3 and g3=0.7.
- The final output is y=0.3⋅y1+0.7⋅y3. This vector y then proceeds to the next part of the Transformer network.
This entire routing and selective computation process happens independently and potentially differently for every single token in the input sequence, allowing the model to adapt its processing pathway dynamically.
The Strategic Advantage: Why MoE is a Game-Changer
The adoption of MoE architectures provides several compelling advantages, fundamentally changing the economics and capabilities of large-scale language models:
- Decoupling Parameters and Compute Cost: This is the cornerstone benefit. MoE allows models to possess a vast total number of parameters, significantly enhancing their capacity to store knowledge and learn complex patterns. However, the computational cost during inference (measured in FLOPs per token) depends only on the number of active parameters (those in the router and the selected K experts).
- For instance, DeepSeek-V2 features an enormous total of 236 billion parameters. A dense model of this size would be computationally prohibitive for inference. But because DeepSeek-V2 only activates 21 billion parameters per token (router + shared experts + 6 routed experts), its inference compute cost is comparable to a much smaller dense model, making it practical.
- Faster Inference: For a given level of performance or knowledge capacity (often correlated with total parameters), MoE models can achieve significantly faster inference speeds (higher throughput, lower latency) than dense models.
- Example: The open-source Mixtral 8x7B model (~47B total parameters, ~13B active) demonstrated performance comparable or superior to the much larger Llama 2 70B dense model on many benchmarks, while being considerably faster and cheaper to run for inference.
- Improved Training Efficiency: While not without its own complexities (discussed next), training MoE models can be more computationally efficient than training a dense model of the same total parameter size. In the backward pass, gradient computation is required only for the router and the K experts that were engaged during the forward pass for each token. This reduces the FLOPs required per training step. However, factors like communication overhead in distributed settings can offset some gains.
- Potential for Richer Representations and Specialization: By having multiple experts, the model gains the potential for these experts to learn specialized roles during training. While this specialization is an emergent property and not typically explicitly programmed, it can lead to more nuanced and capable models.
- Example: Within an MoE layer, one expert might implicitly become adept at handling mathematical reasoning in the input, another at recognizing programming syntax, a third at understanding idiomatic expressions, and a fourth at processing factual statements. The router learns to combine insights from the relevant experts based on the token’s context, potentially leading to richer and more accurate representations than a single, monolithic FFN could produce.
MoE essentially provides a way to get many of the benefits of vastly increased model size (knowledge, nuance) while mitigating the crippling computational cost traditionally associated with it, particularly during inference.
Navigating the Complexities: Challenges of MoE Implementation
Despite their advantages, implementing and training MoE models effectively presents unique challenges that require careful engineering:
- Load Balancing: This is perhaps the most critical training challenge. If the router consistently favors only a few experts, those experts will receive most of the training signals (gradients), while others remain undertrained (“expert starvation”). This wastes parameters and compute resources and harms overall model performance.
- Traditional Solution: Auxiliary Losses: Many early MoE implementations introduced auxiliary loss functions during training. These losses penalize imbalance, encouraging the router to distribute the tokens more evenly across all available experts. For example, a loss term might measure the variance in the number of tokens assigned to each expert and add this to the main training objective, pushing the router towards more uniform assignments.
- Newer Approaches: Expert Choice Routing: Proposed by Google researchers, this flips the script. Instead of tokens choosing their top K experts, each expert selects the top K tokens (from the batch) it is most suited for, up to a predefined capacity. This inherently guarantees perfect load balancing across experts but introduces different implementation complexities (e.g., needing mechanisms to handle tokens not picked by any expert). DeepSeek-AI also mentions using auxiliary-loss-free load balancing strategies.
- High Memory Footprint (VRAM): This is the major trade-off for MoE’s compute efficiency. While only K experts are active computationally for any given token, the parameters for all experts in the MoE layer, plus the router, must be loaded into the accelerator’s memory (GPU VRAM or TPU HBM) simultaneously.
- Example: Mixtral 8x7B requires enough VRAM to hold its ~47 billion parameters, even though only ~13 billion are used per token inference step. This is significantly more memory than required by a dense 13B parameter model, although potentially less than the dense Llama 2 70B it competes with. This high memory requirement can be a significant bottleneck for deploying large MoE models, especially on consumer-grade hardware.
- Communication Overhead: Training and inferring large MoE models typically requires distributing the model across multiple accelerator devices (GPUs/TPUs). A common strategy is “expert parallelism,” where different experts reside on different devices. This means token representations need to be efficiently routed (communicated) from the device holding the router to the devices holding the selected experts, and the results need to be communicated back for combination. This inter-device communication adds latency and can become a bottleneck, especially with slower interconnects. Optimizing communication patterns is crucial.
- Training Instability: The interplay between the router and experts, especially with auxiliary losses, can sometimes lead to training instabilities compared to simpler dense models. Careful tuning of learning rates, initialization strategies, and balancing loss weights is often required.
- Fine-tuning Challenges: Adapting a pre-trained MoE model to a specific downstream task (fine-tuning) requires care. Sometimes, fine-tuning the entire model can disrupt the learned routing patterns or cause overfitting. Strategies might involve freezing certain parts of the model (like the experts) and only fine-tuning the router and other layers, or using very low learning rates.
Addressing these challenges is an active area of research and engineering, crucial for unlocking the full potential of MoE architectures.
MoE in the Wild: Real-World Applications & Examples
MoE is no longer just a research concept; it powers some of the most capable LLMs available today.
- Key Models:
- Mixtral 8x7B (Mistral AI): A highly influential open-source model that demonstrated SOTA performance rivaling larger dense models, popularizing the MoE approach. Uses 8 experts, K=2 routing.
- DeepSeek-V2 (DeepSeek-AI): Another strong open-source MoE model (236B total / 21B active) focusing on efficiency through innovations like Multi-Head Latent Attention (MLA) for KV cache compression and advanced MoE routing. Uses 64 routed experts (K=6) + 2 shared experts.
- GPT-4 (OpenAI) and Gemini (Google): Although their exact architectures remain undisclosed, extensive analyses and reports indicate that these top-tier proprietary models likely leverage Mixture-of-Experts (MoE) techniques to reach their scale and performance levels.
Let’s delve deeper into how MoE’s dynamic routing might play out in specific application domains:
Detailed Example: Programming Assistance
Imagine a developer using an MoE-powered coding assistant with the following multi-part query:
- Part 1: “Write Python code that utilizes the
requestslibrary to retrieve data from a RESTful API endpoint.https://api.example.com/dataand print the JSON response.” - Part 2: “Describe how git merge differs from git rebase.”
- Part 3: “Finally, write a simple React functional component that displays a button and alerts ‘Clicked!’ when pressed.”
- Hypothetical MoE Routing in Action:
- Processing Part 1 (Python/API): As the model processes tokens like
Python,requests,Workspace,REST API,JSON, the router would likely assign high scores to experts that, during training, specialized in:- Python standard library patterns (Expert A).
- Network protocols and web concepts (Expert B).
- Common coding structures and syntax (Expert C). The model activates Experts A, B, and C (assuming K=3 for this example) to generate the Python code snippet.
- Processing Part 2 (Git Concepts): Upon detecting tokens such as explain, difference, git merge, and git rebase, the router adaptively adjusts its routing preferences. It might now activate:
- An expert specialized in conceptual explanations and comparisons (Expert D).
- An expert trained heavily on version control systems and software development practices (Expert E).
- Perhaps Expert C (general syntax/structure) remains somewhat active. These experts collaborate to generate a clear explanation of the Git commands.
- Processing Part 3 (React Component): For tokens like
React,functional component,button,alert,Clicked!, the router again adapts, selecting experts such as:- One focused on JavaScript and frontend frameworks (Expert F).
- One knowledgeable about UI/UX patterns (Expert G).
- Expert C might still contribute for basic code structure. The output is the React code snippet.
- Processing Part 1 (Python/API): As the model processes tokens like
- Key Insight: The power lies in the router’s ability to dynamically orchestrate the activation of specialized computational resources based purely on the semantic content of the input tokens, sequence by sequence. The model doesn’t need separate monolithic models for Python, Git, and React; it leverages specialized parts within a single, larger MoE framework.
Detailed Example: Legal Document Analysis
Consider a paralegal using an MoE-powered legal AI tool to analyze a lengthy commercial real estate lease agreement:
- User Task 1: “Identify and extract all clauses pertaining to ‘Indemnification’.”
- User Task 2: “Summarize the Tenant’s obligations regarding HVAC system maintenance as outlined in Section 8.3.”
- User Task 3: “Does Clause 15, governing ‘Default and Remedies’, align with standard commercial practices in California? Highlight any unusually harsh provisions for the Tenant.”
- Hypothetical MoE Routing in Action:
- Processing Task 1 (Indemnification): When processing the document text and the query tokens
Identify,extract,clauses,Indemnification, the router might prioritize:- An expert trained to recognize specific legal terms and their synonyms/variants (Expert L1).
- An expert skilled at understanding document structure and identifying clause boundaries (Expert L2).
- An expert focused on extraction and information retrieval patterns (Expert L3).
- Processing Task 2 (HVAC Summary): As the model focuses on Section 8.3 and the terms
Summarize,Tenant's obligations,HVAC system maintenance, the router could activate:- An expert specializing in summarizing technical or contractual language (Expert L4).
- Expert L2 (document structure) to stay within Section 8.3.
- An expert possibly trained on real estate or facilities management terminology (Expert L5).
- Processing Task 3 (Clause 15 Analysis): For analyzing
Clause 15,Default and Remedies,standard commercial practices,California,unusually harsh, the router might engage:- An expert trained on comparative legal analysis and jurisdictional differences (Expert L6, potentially specialized for California law).
- An expert adept at identifying risk, bias, or non-standard language in contracts (Expert L7).
- Expert L1 (Legal term identification) and Expert L4 (summarization/clarification).
- Processing Task 1 (Indemnification): When processing the document text and the query tokens
- Key Insight: The MoE architecture allows the AI to apply different forms of “legal reasoning” dynamically. It can shift from term spotting and extraction to summarization to comparative analysis by activating different combinations of its internal experts, all orchestrated by the router based on the specific task and the text being analyzed. Experts might even implicitly specialize in different areas of law (contract, tort, corporate) or jurisdictions.
Brief Mentions of Other Domains:
- Finance: An MoE model could route queries about stock market analysis to quantitative experts, questions about banking regulations to compliance experts, and customer service chat interactions to conversational experts.
- Healthcare: Processing patient symptoms might activate diagnostic suggestion experts, summarizing a research paper could use medical literature experts, and drafting patient communication might engage empathetic language experts.
- Creative Writing: Generating poetry might use experts specialized in figurative language and meter, while technical documentation could leverage experts focused on clarity and precision, and dialogue writing could tap into experts trained on character voice and interaction patterns.
The Horizon: Future Directions for MoE
The field of MoE is evolving rapidly. Research continues to push the boundaries:
- Smarter Routing: Moving beyond simple Top-K. Techniques involving dynamic K (selecting a variable number of experts based on token complexity), hierarchical routing, or incorporating longer-range context into routing decisions are being explored.
- Memory & Communication Optimization: Developing techniques to reduce the VRAM burden, perhaps by cleverly swapping experts between main memory and accelerator memory, or designing more efficient communication protocols for distributed MoE. Innovations like DeepSeek’s MLA, while focused on the KV cache, reflect the broader drive for efficiency.
- Enhanced Training Stability & Controllability: Discovering more robust training recipes and exploring methods to exert more explicit control over expert specialization during training.
- Hardware Co-design: Designing future AI accelerators (GPUs, TPUs, NPUs) and interconnects specifically optimized for the sparse computation and communication patterns inherent in MoE workloads.
Conclusion: The Era of Sparse Computation
Mixture-of-Experts represents a fundamental paradigm shift in how we build and scale large language models. It cleverly breaks the rigid coupling between model size (knowledge capacity) and computational cost (inference FLOPs), allowing for the creation of vastly more capable models within practical resource constraints.
While MoE introduces its own set of challenges – particularly around memory requirements, training complexity, and communication overhead – the benefits in terms of computational efficiency and scalability are proving transformative. It’s not merely a passing trend but a cornerstone technology enabling the continued advancement of state-of-the-art AI. As research progresses and engineering solutions mature, MoE architectures are poised to become even more prevalent, driving the next generation of powerful, efficient, and perhaps even more specialized, artificial intelligence. The era of dense, monolithic models is giving way to the era of smarter, sparser, conditional computation.
See also in our AI category: Multi-head Latent Attention (MHA) Explained




1 thought on “Scaling Smarter, Not Harder: A Deep Dive into Mixture-of-Experts in Modern LLMs”